
Papers I've read this week: vision language models
They kept releasing VLMs, so I kept writing...

I’ve been on a VLM kick lately, trying to read as many papers about vision language models as possible. This was inspired by Claude being ridiculously good at converting equation screenshots to LaTeX, which made me want to understand how LLMs can be so good at understanding pictures and doing fancy OCR. I remember using Tesseract and ABBYY FineReader back in the day, and finding them slow/hard to work with. Now, with VLMs, it seems like reading text from pictures is a solved problem? Definitely surprised me.
In any case, I realized that I didn’t have a good understanding of how VLMs worked, so I wanted to change that. Here’s the results of my efforts to change that!
Funnily enough, 2 VLMs have been released since I started writing this: Pixtral, and DeepSeek Janus, both causing the article to be delayed.
Spoiler: it’s actually super straightforward. It turns out that using some vision encoder (typically a ViT, initialized from a good open source model) to convert images into features, patchifying it, and concatenating the resulting sequence with the text embeddings, is basically enough. There are some fancier architectures, but they don’t seem noticeably better.
I will be giving a talk as part of the PyTorch Expert Exchange lecture series on how batching works on modern GPUs, based on the article I wrote last year. Please join me!
Finally, this article is long. You might want to read it on the web instead.
The evolution of multimodal model architectures
[abstract]
I began my mission to understand VLMs with this survey paper from Purdue. It’s a high-level overview of multimodal architectures, grouping them into 4 categories:
Type A and Type B, which combine multimodal inputs within the internal layers of the model
Type C and D, which combine the modalities at the input stage.
Type A employs cross-attention, while B uses custom layers for modality fusion.
Type C uses modality specific encoders, while D uses tokenizers to convert every mode into tokens, and then processes them together.
Examples of models which fall into the various categories:
Type A: Flamingo, and various Flamingo derived models
Type B: CogVLM, MoE-LLaVa
Type C: DeepSeek-VL, LLaVa, Sphinx, Emu, Qwen-VL
Type D: LaVIT, Unified-IO
Contemporary open source models are almost all doing Type C. Type D is somewhat common in video models (e.g. MagViT2) but most multimodal papers aren’t bothering to convert the image features into tokens, but passing the patchified features directly into the decoder.
Of the papers that are notable to me, Type C seems dominant. I suspect that most closed models, like Reka, Claude, and Gpt4o, are doing Type C. My logic is that, in deciding between deep fusion, where modalities are combined within the internal layers of the model, and early fusion, where they’re combined at the input, the large labs will be focusing on the most general approach, and follow the bitter lesson, which states that we should learn as much of our structure as possible, rather than imposing pre-determined inductive biases.
The paper is useful as an overview, but it does get bogged down in coming up with a detailed taxonomy of VLMs which I think is of questionable utility. Great intro if you’re unfamiliar with the space.
Flamingo
[abstract]
Published in April ‘22, Flamingo was one of the early multimodal LMs. It focused on enabling zero-shot adaptation to novel tasks that use text and image inputs. They evaluated on 16 tasks, and reached SOTA in 6 of them despite using ~3 orders of magnitude less task-specific data (yet another win for the bitter lesson!). The architecture is interesting; they combine a pretrained & frozen vision encoder with a similar frozen & pretrained language model, and only train dense cross-attention layers, along with a Perceiver Resampler layer on the top of the vision encoder. This is a much more complicated architecture than we’ll see in later models, which tend to all be decoders with minor tweaks.

The core idea is that they have a Perceiver Resampler on top of a frozen vision encoder which takes visual inputs and outputs a fixed number of tokens. These are used to condition a frozen LM (various Chinchilla models) using freshly initialized gated cross-attention layers.

The model seems to work well, but was very complex. With the benefit of hindsight, it’s interesting how unnecessary the complexity was, as none of the subsequent SOTA models used a similar architecture.
Qwen-VL
[abstract]
Published in August 2023, this is when we start to see architectures/training methodologies arise that are very similar to the state of the art in Q3 2024. The Qwen-VL series of models are based on the Qwen LLM, and add visual capacities. They claimed significant improvements in the SOTA compared to other open VLLMs as of Q3 2023. The model architecture is fairly similar to what we’ll see moving forward; they use a ViT-bigG, initialized from Openclip’s model, and resize images to 224x224, splitting the images into patches. They then use a vision-language adapter to compress the image features. The adapter is a single layer of cross attention, which uses a number of learned embeddings as query vectors and the image features from the visual encoder as keys for cross-attention, outputting a sequence of length 256. They use 2D absolute positional encodings on the output of the cross-attention layer. They have three stages of training during which they freeze various parts of the model.
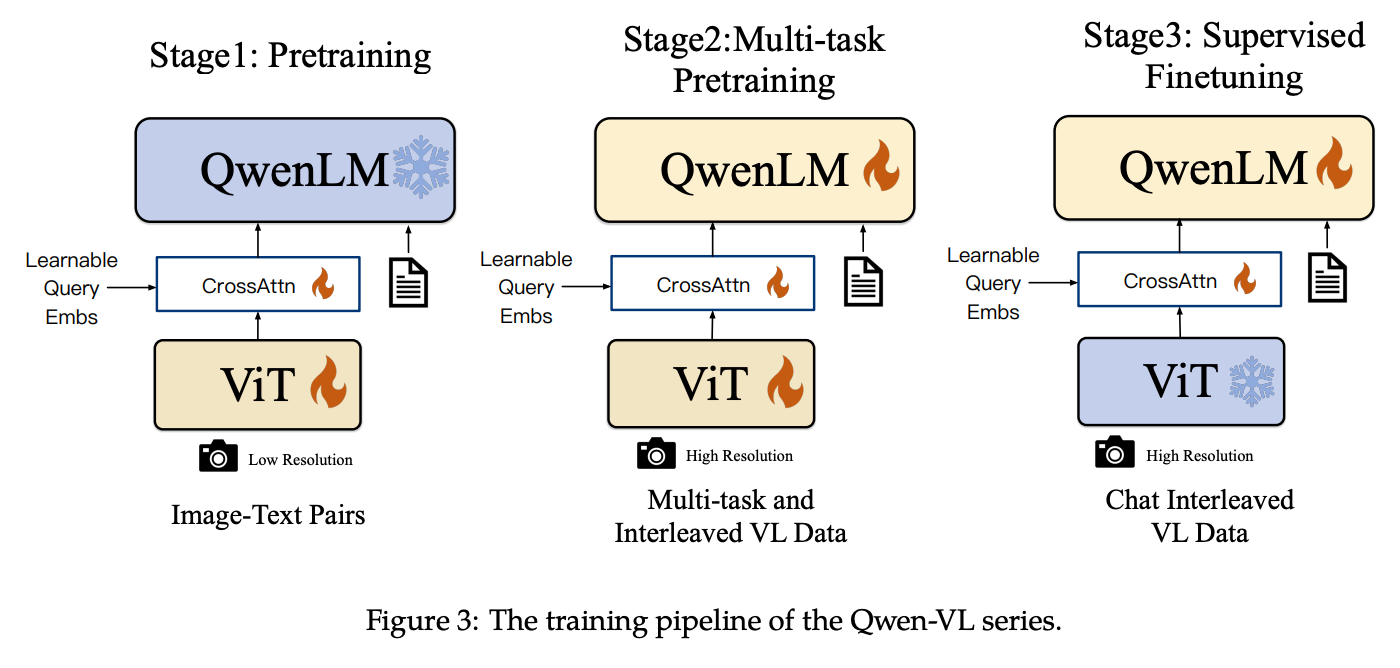
They add special tokens (<img>, </img>) to the sequence to denote the start/end of image content, and also train the model with bounding boxes, including them as text tokens which are tokenized in the standard way, but with two types of special tokens: <box>, </box> to denote the coordinates, and <ref>, </ref> to denote the text description corresponding to a given bounding box.
The model is pretrained on web-scraped image-text pairs, and then trained on high-quality, fine-grained annotation data. They have an additional supervised fine-tuning stage that they use to create a Chat model. The result is quite strong, and achieves SOTA in a variety of tasks.
CogVLM
[abstract]
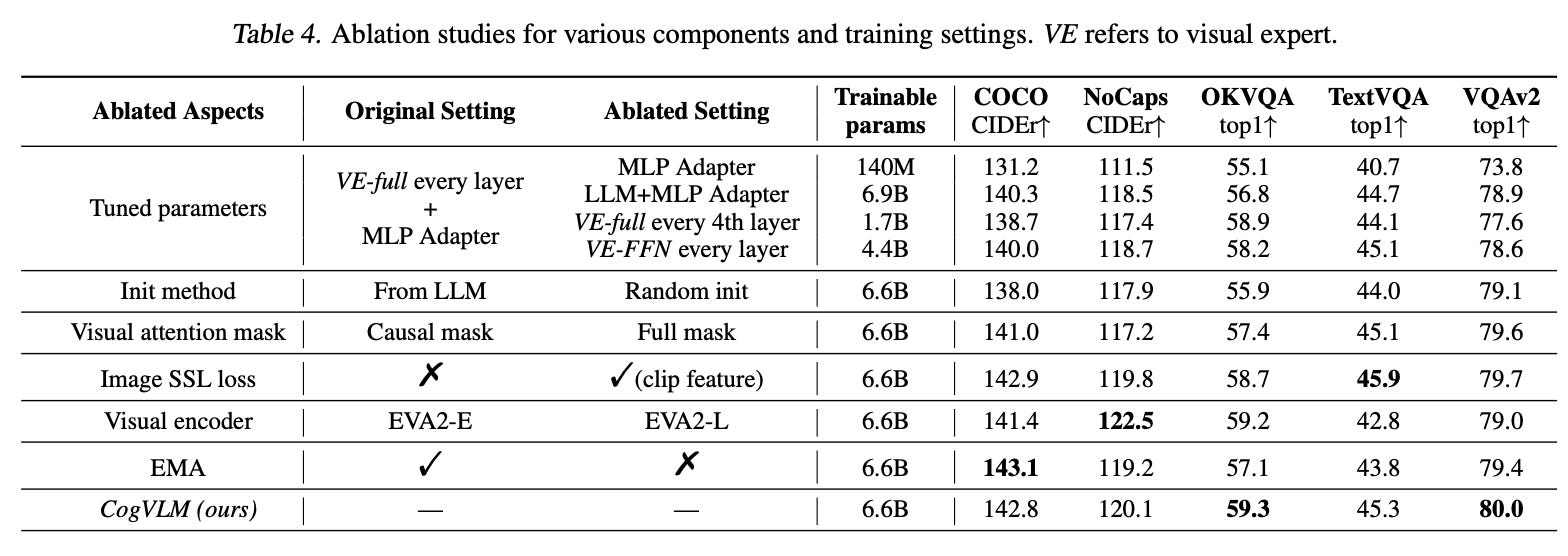
Published in late 2023, CogVLM uses a frozen trained language model and image encoder, and combines the two with a trainable visual expert module in the attention and FFN layers, enabling vision features without sacrificing NLP performance. It is SOTA across a number of multi-modal benchmarks. This was likely implemented contemporaneously with Qwen-VL, but definitely has more in common with the pre-Qwen architectures like Flamingo.

They add two trainable layers to each transformer block: a MLP, and a QKV matrix, initializing them from their pretrained counterparts in the language model.
Interestingly, they assign all the image tokens a single position ID for RoPE, with the logic that visual tokens already encapsulate positional information when inputted into the ViT, and that by adding additional positional information, the query would focus more on the closer tokens, i.e. the the lower part of an image.
The authors did a lot of ablation experiments to justify the choices they made. These are great and really informative for training VLMs.
DeepSeek-VL
[abstract]
From March 2024, the DeepSeek take on a VLM appears to be a refinement of the Qwen-VL approach. For the visual feature module, the authors use a hybrid encoder, which has a text-aligned encoder for coarse semantic extraction at 384x384 resolution with a high-resolution encoder that operates at 1024x1024 resolution. The module represents a 1024x1024 image as 576 tokens. The high-resolution encoder is based on SAM-B, while they use SigLIP-L for the low-resolution image inputs. SigLIP can generally be viewed as a “better CLIP” so this is a modernization/improvement on what Qwen-VL did.
The authors use a two-layer hybrid MLP as a vision-language adapter, with two distinct single-layer MLPs processing the high- and low- resolution features separately; these features are then concatenated together, and transformed into the LLM’s input space through another layer of MLP.
The authors pretrain the models beginning with an intermediate checkpoint from DeepSeek-LLM, and continue to use extensive text-only data, with 70% of the tokens seen during training coming from the DeepSeek text-only corpus. The authors keep the LLM and the vision encoders frozen while they train the vision-language adaptor module, and then jointly train the LLM + VL adaptor on interleaved VL + text-only sequences. Finally, they finetune the entire model on chat data, unfreezing everything.

The authors achieve SOTA in the majority of the benchmarks they evaluate when compared against other open-source 7B models. Unsurprisingly, the proprietary LLMs, like GPT4 or Gemini Pro, are significantly better (and presumably significantly larger). Their model doesn’t see significant degradation on language benchmarks, which has consistently been a problem plaguing VLMs, which tend to have rapidly degraded performance on LLMs; I suspect that the large % of text-only pretraining data was sufficient. This is a good counterexample for the frozen text models we’ve seen consistently.
Chameleon
[abstract]
Published by Meta in May of ‘24, Chameleon is what I would think of as a great example of a “modern” multimodal model which uses early fusion to treat all modalities as discrete tokens. The loss here is the standard autoregressive loss, with <start_image> / <end_image> tokens being used to insert the image tokens into the sequential input. Chameleon achieves SOTA on a number of benchmarks (visual question answering, image captioning), and is competitive with text-only models of a similar size (Mixtral 8x7B, Gemini-Pro).

The authors train the model on a variety of orderings, including text-only, text-image pairs, and full interleaved text-image documents. This is, notably, the model that was trained with the most compute and the only one trained from scratch. As you’d expect, performance is quite strong.
For the image tokenizer, they use Make-A-Scene, encoding a 512x512 image into 1024 discrete tokens, using a codebook with size 8192. The authors note that this tokenizer is particularly bad at reconstructing images with a large amount of text, which is to be expected given the codebook size. They use a standard BPE tokenizer for text. They are one of the only VLMs that actually tokenizes their images rather than passing image features directly into the decoder.
The authors ran into stability issues when training models with more than 8B parameters & 1T tokens, with instabilities happening late in training. They used a Llama2 architecture, with RMSNorm, SwiGLU, and RoPE. They found that the softmax operation was leading to complex divergences because the different modalities had significantly different entropy, so the different modalities would “compete” with each other by trying to increase their norms, which would eventually explode. This is similar to the logit drift problem in the text-only setting. Consequently, the authors used QK-Norm and added dropout after the attention & feed-forward layers, which was enough to stabilize their 7B model. To stabilize their 34B model, they also had to reorder the norms, like so:

The changes were quite dramatic, which violates my intuition. I did not expect norm reordering to have such a big impact on the training loss, although pre/post layer normalization has had a significant impact in certain settings, so I should perhaps not be surprised.

They found that dropout wasn’t necessary with norm reordering, but QK-Norm was. This makes sense; I think QK-Norm should generally be used by default.
PaliGemma
[abstract]
From July 2024, PaliGemma continues to demonstrate the superiority of Lucas Beyer’s SigLIP loss, combining a 400M SigLIP model with a 2B Gemma model into a <3B VLM that is SOTA on a variety of tasks despite being (relatively) small.
SigLIP, standing for Sigmoid loss for Language Image Pre-training, is a loss that operates solely on image-text pairs and does not require a global view of the pairs for normalization. It can be thought of as a replacement for CLIP. It is defined as:
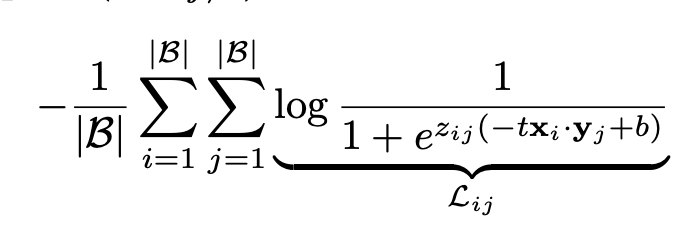
Where $x_i$ is the normalized feature embeddings from the image datapoint, and $y_j$ is the normalized feature embeddings from the text datapoint, and $z_{ij}$ is 1 if the image and text datapoints are paired, and $-1$ otherwise (no, your browser isn’t broken— there’s no good way to do inline math with Substack, unfortunately). PaliGemma uses a SigLIP image encoder to provide image features which are concatenated with the text tokens and processed by a standard decoder.

Unlike Flamingo, the entire PaliGemma architecture is trained jointly on multimodal tasks, with nothing being frozen. Unlike Chameleon, the individual components are initialized from previously trained models (SigLIP 400M and Gemma 2B). It is very similar to DeepSeek-VL.
PaliGemma was SOTA on the MMVP benchmark (47.3%), and did well on the rest. This is remarkable given how small and (relatively) cheap it was to train. Notably, it beat GPT4-V (38.7%) and Gemini (40.7%) on this task. That’s remarkable given that these models presumably are much bigger and saw much more data during training.
{kind=link}
Pixtral (12B)
[abstract]
From October 2024, Pixtral is a 12B parameter multimodal model, using a vision encoder trained from scratch which ingests images at their natural resolution and aspect ratio, allowing it to vary the number of tokens used for an image. It has a long context window of 128k tokens.
Pixtral also has a novel RoPE-2D implementation.
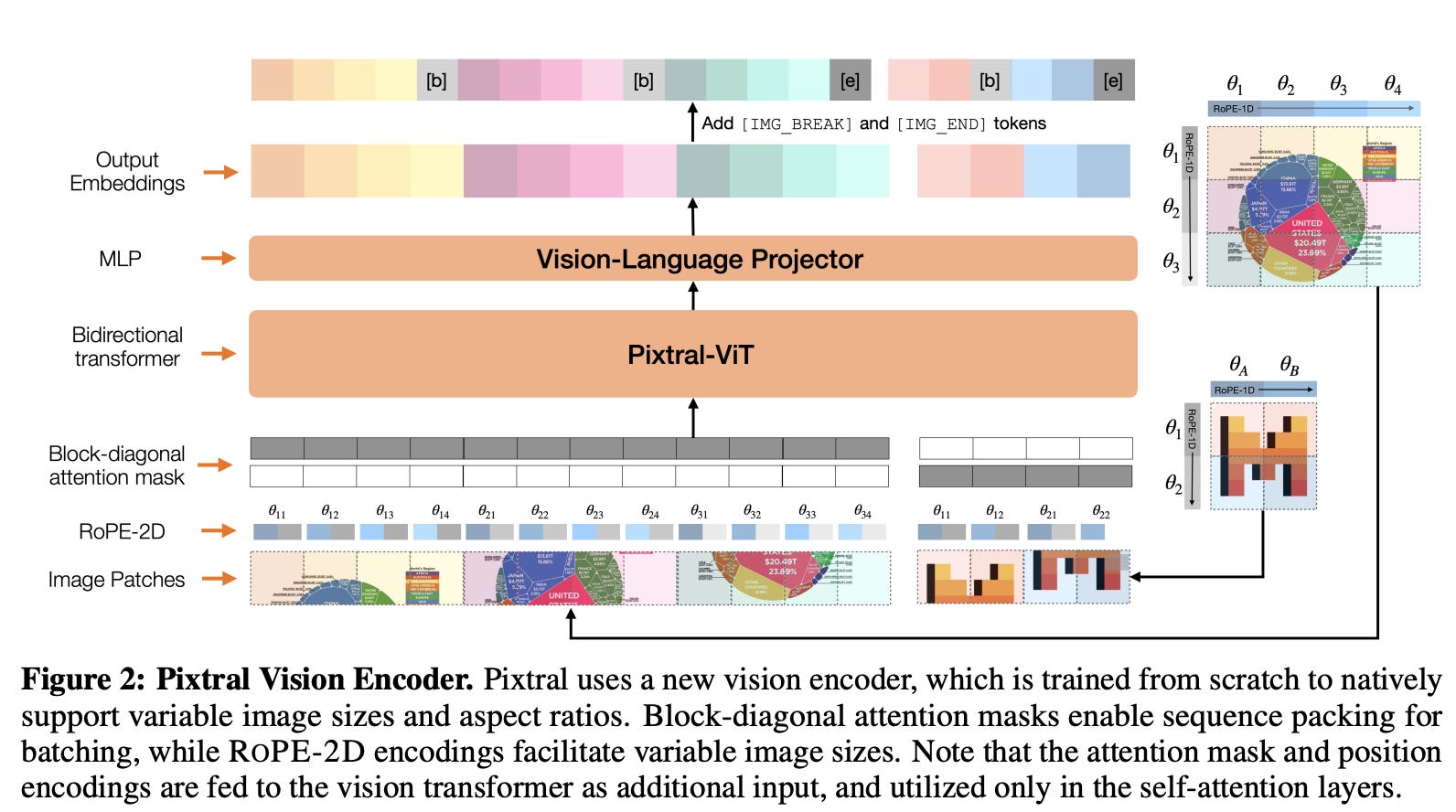
It is based on Mistral Nemo 12B. They train a new vision encoder from scratch, Pixtral-ViT, which is a 400M ViT. It has 4 key changes vs a typical ViT:
They include
<IMAGE_BREAK>tokens between image rows (as they scan patches in raster order), and include an<IMAGE_END>token at the end of an image sequence.They use gating in the hidden layer of the FFN.
To efficiently process images, they use sequence packing, flattening images along the sequence dimensions and concatenating; they then use a block-diagonal mask to ensure no attention leakage happens.
RoPE-2D. They replace the standard learned & absolute position embeddings for image patches with relative, rotary position encodings. The function is kinda complicated:
\(\text{Rope2D}(x^{(i, j)}, \Theta) = M_{\Theta}^{(i, j)}x^{(i, j)},\)where $M_{\Theta}^{(i, j)}$is a diagonal block matrix such that $M_{\Theta}^{(i, j)}[k: k + 2, k: k+2]$ are the only non-zero entries, with each 2x2 block being equal to
\(\begin{matrix}\cos l \theta_1 & -\sin l\theta_1 \\ \sin l \theta_1 & \cos l \theta_1 \end{matrix}\)where $l = i$ if $k$ is odd, and $j$ otherwise, with $\Theta = [θ1…θd/2]$is a vector of frequencies for the various dimensions of $x$, where $\theta_m$ is defined following standard, 1D RoPE.
Their implementation satisfies the “relative” property, where inner products between two vectors depend only on their relative difference in height/wodth indices, which is generally agreed to be highly desirable.
The Pixtral vision features are included in the decoder via a two-layer fully connected network, using a GeLU activation on the intermdiate, hidden layer. Image tokens are treated identically to text tokens by the multimodal decoder, including RoPE (1d) embeddings for each token, in particular using causal attention. It’s a complicated architecture but has some nice properties, particularly the variable length, native resolution image encoding.
Unfortunately, there’s no information provided about how they trained the models, and in particular, about whether or not the LLM/vision encoder were frozen during training. The model is notable for being (relatively) quite large, at 12B parameters. That’s much more than the other models discussed here.
DeepSeek Janus
[abstract]
Well, as mentioned above, I was about to publish this article, and DeepSeek released Janus. Janus is a fascinating piece of work as, in true DeepSeek fashion, it’s an actual novel architecture. DeepSeek has two visual encoders: one for visual understanding, and one for image generation.

Otherwise, the architecture is basically the same as what we’ve seen before, a typical “early fusion” model that uses a pretrained LLM to process the visual features. The visual understanding model uses a SigLIP encoder to extract visual features, which are then flattened into a 1D sequence, and they have an “understanding adaptor” which maps these image features into the input space of the LLM. For visual generation, they use a VQ tokenizer from LlamaGen to convert the images into sequences of discrete IDs, which are then transformed into embeddings via a generation adaptor. The result is a multimodal sequence that is fed into the decoder model. They use a tree-stage training process which is, again, very similar to other models (particularly, and unsurprisingly, DeepSeek-VL):

Their loss function is simply cross-entropy, and for understanding tasks (either text or multimodal) they compute the loss only on the text sequence, while for visual generation tasks, they compute the loss only on the image sequence. During inference, they use CFG in the standard way, with a scale of 5. They claim SOTA on generation when compared to some older models, e.g. DALLE-2, SDXL, etc., when evaluated on the GenEval benchmark, which, while interesting, is not particularly compelling. I’d prefer to see an Elo ranking vs the most commonly used standard models, such as Flux. The model appears good at prompt following, but not particularly aesthetic; I suspect it would fair poorly against, say, Flux. Having said that, the model performs very well for a 1.3B model.
Conclusions
With Chameleon, Pixtral, and PaliGemma, it looks like training methodologies are starting to converge. I think that the architecture used by Pixtral (and the pretraining recipe used by Chameleon) will basically be the recipe that most SOTA VLMs are using, if they’re not already.
Something worth noting is how (relatively) little compute was used to train many of the open source VLMs. The biggest LLaVa model used 768 A100 hours. DeepSeek-VL used 61440 A100 hours (512 A100s for 5 days). PaliGemma used ~12k A100-equivalent hours (18k TPU v5e hours).
Compare to, say, MovieGen, which used 6144 H100s for an unknown amount of time, or Stable Diffusion, which used 150k A100 hours. Presumably the large AI labs are using much more compute/data to train their models; Chameleon, for instance, using 10T tokens, is much more in line with what I would expect for a SOTA model.
The two big decisions that have to be made when training a VLM appear to be 1) how to combine image/text inputs and 2) whether or not to train the visual & language features separately. CogVLM did very well with a 17B model with keeping the models frozen. DeepSeek-VL trained everything after some careful freezing during pre-training. Chameleon trained everything from scratch. I think that it’s obviously cheaper with little to no degradation in quality to use a pretrained encoder, so I think that’s the route to go with. And “early fusion”, where the image features are concatenated to the text embeddings, seems elegant while performing well. That is probably the route I would go (basically following PaliGemma).
In short, the standard recipe appears to be:
Use a ViT for the image encoder, initialized from a large open source model (SigLip, Clip, etc.)
Use a pretrained LLM as the base model
Finetune the combined model
I see no evidence that it makes a difference whether we add the image/text data as inputs to the model, or do some fancier combination deeper in the model, like CogVLM or Flamingo did. The more recent models, like Qwen or DeepSeek, do well just having the image features added to the sequence data.
Finally, another reminder that I will be giving a talk as part of the PyTorch Expert Exchange lecture series on how batching works on modern GPUs, based on the article I wrote last year. Please join me!