
Efficient LLM inference
On quantization, distillation, and efficiency

Lately, I’ve been thinking a lot about inference, and particularly, how to serve a given LLM more efficiently. The scenario is as follows: Your boss comes to you and says Hey Finbarr, we’re about to go bankrupt because we’re spending all of our investor’s money on GPUs serving our 300B parameter model that raps in the style of John Kenneth Galbraith. What can we do?
Broadly speaking, there are three main classes of things you can do:
You can quantize the parameters of your model (quantization), where you keep your model exactly the same, but use less precision for each of the parameters.
You can distill a smaller version of your model (distillation), where you copy the architecture of your model to make it smaller and/or more efficient and then train this new, smaller model to mimic the outputs of the original, large model.
You can spend a bunch of time profiling your code and reduce the overhead without changing the architecture or parameters (optimization).
The first place to start, somewhat obviously, is optimization. The amount of overhead that most programs have is ridiculous, and by simply profiling1 your code, you can often find surprising amounts of overhead. For instance, I once had a colleague ask for help optimizing his code. He was training a neural network to perform a sophisticated calculation and had implemented a bunch of performance optimizations to make that faster, but he was also using a list to do lookups in a performance critical loop. I changed the list to a dict and made the code 200x faster.
This isn’t a rare occurrence. Every time I’ve profiled code, I’ve been surprised at the resulting profile. So if you’re having performance issues (don’t worry, it happens to all of us, it’s natural), the first thing you should do is profile your code.
For most people, this will be sufficient. Just removing the overhead from your code and batching requests in the naive way will get you to the point where you can serve requests in a cost-effective manner, particularly if you have traditional software margins. But let’s say that you’ve done a bunch of profiling and you’re now at the point where the only remaining optimizations are implementing arcane kernels in Triton which requires hiring grizzled old CUDA experts away from Nvidia. What’s the next step you can take to use your GPUs effectively?
Now, you’re left with quantization and distillation. Quantization, where you use less precise weights for your neural network without changing anything else about it, has been talked about a lot lately. Llama.cpp, for instance, used this to great effect to reduce the memory required to store the llama weights by 4x.
Distillation has received less attention but has historically been an important part of serving models at scale. This is because distillation generally works much, much better than quantization, and if you have the resources, should be the way you do things.
There’s a key caveat there: if you have the resources.
Let’s go back to our hypothetical scenario. You’re a hardworking ML engineer at CoherentOpenStability, where you’re trying to reduce the inference costs for your latest and greatest LLM, StableClaudius-4. You’ve already profiled your code and reduced all of the overhead that you can. You now have a few options:
You come up with a research breakthrough which lets you accomplish the same thing, for cheaper. E.g. you design a new sparse attention mechanism which works well.
You make your model smaller.
If I were to compare these, the obvious winner is #1. If you can come up with a novel research contribution that magically improves your model, you should obviously do that. If this is you, stop reading this article, go write a paper, apply to OpenAI/Anthropic/DeepMind, and collect a ridiculously high salary for being a large language model whisperer. Most of us cannot do this. So we’re stuck trying to come up with a smaller model that accomplishes the same things.
How should we come up with a smaller model? A few options:
You train a smaller model in the exact same way as your original model.
You distill your big model into a smaller model.
You quantize your existing model.
In my opinion, the literature indicates a clear & obvious ranking: distillation is strictly better than training a smaller model, and quantizing is probably better than training a smaller model.
There aren’t as many distillation papers as I would like, but the two that come to mind are DistilBERT and the original distillation paper from Hinton et. al. In DistilBERT, the authors reduce the model size by 40% while only hurting performance by 3%.
In the Hinton et. al paper, they’re able to match the performance of an ensemble of 10 models with a single, distilled model, and performance only decreases from 61.1% accuracy to 60.8% accuracy (99.5% of the original performance, with 10% of the size). Now, the Hinton paper is comparing against an ensemble, which is a particularly wasteful way to increase model size, but that’s still impressive result, and much better than training a model from scratch to perform the same task (which had only 58.9% accuracy).
The problem with distillation, however, is that it requires training a smaller model from scratch and running inference over your entire dataset with your large model. If you have a dataset the size of GPT-3 (500B), this would cost $1M at public API prices (5e11 tokens * 2e-6 $/token = $1e6), or $400k if we assume OpenAI has a 60% margin. Given that it cost approximately $5M to train GPT-3 initially, this would add 10-20% to that already large cost. Not prohibitive, but expensive.
If you can afford this cost, great! Do it. It’s almost certainly going to give you the best performance. If you want something cheaper, you’re deciding between training a smaller model from scratch and quantizing an existing model. To help, we have a paper k-bit inference scaling laws. The idea is that, from an inference perspective, we’re agnostic between serving a 30B model at one level of precision and serving a 60B model with twice the level of precision, as most GPUs are twice as fast at running models with half the precision (e.g. A100s).

This figure shows the tradeoff between using various model sizes with various levels of precision. Let’s compare two points for the OPT line of work.
Model precision Bit precision Mean zeroshot accuracy $10^{11}$ 8 0.675 $10^{11}$ 16 0.65 $10^{12}$ 8 0.725 $10^{12}$ 16 0.7
What we see is that, given a total number of model bits, we prefer the model with fewer bits per parameter. Intuitively, this makes sense: we don’t see a benefit from training half as many parameters with fp64 vs fp32.
If we look at another figure, this time from the OPT paper, we can analyze how performance scales with the number of parameters. As OPT uses FP16, which uses 2 bytes (or 16 bits) per parameter, 1e11 parameters is equal to 1.6e12 bits. By using 10x less parameters, and going from 1.6e12 to 1.6e11 bits, the average accuracy for OPT goes from 0.7 to 0.65: a 10x decrease in cost for a 8% decrease in accuracy. Not quite as good as the model size/accuracy tradeoffs we see with distillation, but I think that most businesses would have to strongly consider the tradeoff.
The other thing to keep in mind about quantization is that it’s remarkably cheap to do! The SOTA method for quantization is GPTQ, which can quantize a 175B parameter model in 4 GPU-hours (roughly $4 of cost at public cloud prices). Training the model from scratch, on the other hand, costs a lot; a rough estimate of the cost to train a GPT-3 style model is $5M for the full model, with cost scaling linearly in the number of parameters, so a 20B model would cost ~$500k, and requires a lot of data (~100B tokens to be Chinchilla optimal).
So quantizing is great. But what, exactly, is quantization, and how does it work?
The idea behind quantization is simple. Computers, due to their discrete nature, can’t natively store floating point numbers. digital numerical representations are based on bits, namely 1s or 0s. These bits are assembled into binary. In a binary integer representation, you can represent a range of
using a signed integer, where n is the number of bits. One bit is reserved to represent whether or not the number is positive or negative, and n - 1 bits are used to represent the magnitude.
This works well, and is reasonably efficient. However, the problem comes when you want to represent the real numbers, i.e. numbers that can take on values between integers. The most common approach is to reserve 1 bit to indicate the positivity/negativity of the number, m bits to represent the magnitude of the number (the exponent), and (n - m - 1) bits to represent the precision of the number (the significand)

The significand is just a (n-m-1)-bit unsigned integer, and can thus represent values up to 2^{n - m - 1}.
In a 32-bit floating point number (single precision), 1 bit is used for the sign, 8 bits for the exponent, and 23 bits for the significand.
In a 16-bit floating point number (half precision), 1 bit is used for the sign, 5 bits for the exponent, and 10 bits for the significand.
In a 64-bit floating point number (double precision), 1 bit is used for the sign, 11 bits for the exponent, and 52 bits for the significand.
Note where the additional bits are going— they are mostly going to the significand, which adds precision, rather than magnitude. In other words, this lets us distinguish between smaller numbers, rather than allowing us to represent bigger ones.
By default, all major tensor programming frameworks use 32-bit precision to store trainable parameters. There’s a reason for this: 32-bit precision tends to be a good default. There are very few applications which benefit from the additional precision (mostly scientific computing applications). However, in practice, most of the bleeding edge work now uses 16-bits.
But ok. Now that you’ve read through my digression on how precision works in floating point numbers, let’s say we’ve chosen a level of precision. How do you actually lower the precision of your weights? The naive approach is to simply truncate your weights at a given level of precision. As a simple example, if your weight is 0.534345, naive truncating the weights will convert it to 0.534.
The SOTA model for quantizing to 4-bits or below is GPTQ. Some other methods are LLM.int8() and ZeroQuant. I’ll discuss these in depth in a future article, but here, I’ll focus on GPTQ. The basic idea behind GPTQ is that, while there’s necessarily a drop in information contained within the network by reducing the number of bits, we can reduce the impact it has on inference accuracy by training weights to directly minimize the difference between the two:

Let’s walk through an example. Let’s say that x = 0.323, and as above, w = 0.534345. Then, keeping everything as a float32, the activation output is:
which, rounded to 6 decimal points (the precision for float32s), gives us an output of 0.172593.
Rounding naively, our output is
The difference here is 1.114e-4. If we use GPTQ, we solve
which gives us
which, rounded to 3 decimal points (the precision for float16s)… gives us precisely the same answer as naively rounding, but with more effort.
Presumably this would matter more in other scenarios? I haven’t been able to come up with a simple example that makes GPTQ worth it. But in actual deployment scenarios, GPTQ claimed a significant difference (RTN meaning “round to nearest”):
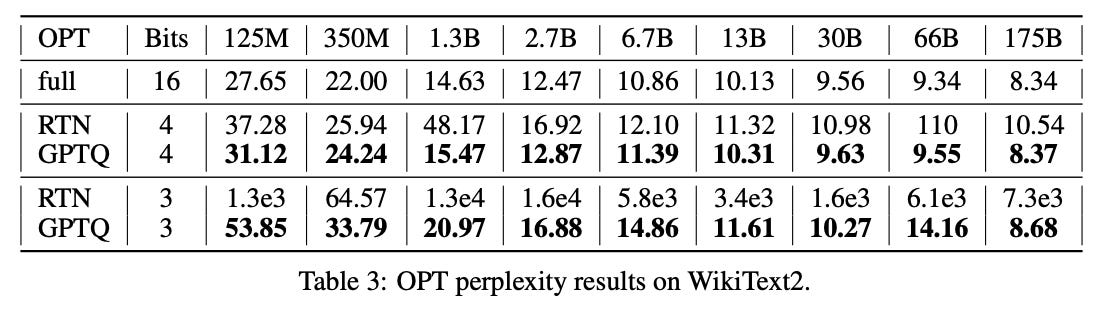
So this is a method that works much better than naively rounding, and is cheap.
Conclusion
Quantization isn’t magic. Ultimately, you’re always sacrificing accuracy for performance. Maybe you won’t lose a lot. But you’ll never gain accuracy, so at best you’re staying the same.
It’s also unclear how often the tradeoff is worth it. Tim Dettmers scaling law for quantization. If you’re using half the precision, it might be worth using the same precision and half the weights and training for twice as long on more data. This is what, for instance, replit did. For many practitioners, the cost to serve a model heavily outweighs the cost to train the model. If this is you, you might not care about quantizing one.
Even if you do, distillation will typically outperform quantization. So if you can distill the model, you probably should. It’s only when you don’t have the resources to do this that quantization is clearly worth it.
Finally, with quantization, you only get a linear speedup as you decrease the number of bytes. That’s pretty good! But ideally we’d want to see much better scaling. Perhaps some sort of sparsity will do better.
Not even using a fancy GPU profiler, but just profiling the program as a whole using the basic profiler for your language!
Thanks for the post,
Most model weights I have seen are floating points between -1 and 1, If we got rid of the exponent bits wouldn't we be able to save ~31% model weight size in a 16 bit floating point?
Presumably this would require changes in the underlying hardware itself, in order to perform calculations with this new floating point.
But still find it bizarre that ML models have all these useless bits lying around.
The part about GPTQ is pretty bizarre - I would've thought quantization is just doing what you showed at scale. Maybe it works because it does that rounding operation in a vectorized operation? Rather than naive rounding which is slower? That doesn't sound like I'm saying anything intelligence. A tad funny that we don't know exactly why quantization works.