
Where do LLMs spend their FLOPS?
LLM theory, with a hint of empirical work

Ok folks. I had a longer holiday break than expected thanks to some family illnesses. I’m still lowering adjusting my expectations for how often I can expect to be healthy, now that I have a toddler. Sickness. Lots, and lots of sickness.
This is a long article, so you might want to bookmark this and read it on your computer, not your phone.
Here, I conduct a theoretical analysis of LLM performance, and then profile an actual LLM to see where the empirical results differ from the theory. First, the theory. I will rely on the excellent blog post by Kipply to fill in the details. The basic takeaway is that for a standard decoder model, our FLOPS are allocated as follows (on a per-layer basis):
6 d^2 to compute QKV
2d^2 to compute the attention output matrix,
softmax(Q @ K.T) @ V16 d^2 to run the FFN
The sum is 24d^2 FLOPS. Percentage-wise, we spend 25% of the time computing QKV, ~8% computing the attention output matrix, and ~66% of the time running the FFN.
What about the attention mechanism? Well, as everyone knows, the attention equation is
With a KV cache (you are using a KV cache, right anon?), Q, K, and V are all d-dimensional vectors (equivalently, (d, 1) matrices). So it takes ~2d flops for each dot-product and d flops for the d divisions that happen, for a total of ~5d flops, rounding to nothing:
For d equal to 4096 (the value it takes in Llama7b) this is 0.005%, so nothing. This makes it seem like the attention mechanism doesn’t matter, but of course, we only use a KV cache (and flash attention, etc.) because it matters so much. Think of Milton Friedman’s thermostat analogy (h/t @bradchattergoon):
If a house has a good thermostat, we should observe a strong negative correlation between the amount of oil burned in the furnace (M), and the outside temperature (V). But we should observe no correlation between the amount of oil burned in the furnace (M) and the inside temperature (P). And we should observe no correlation between the outside temperature (V) and the inside temperature (P).
An econometrician, observing the data, concludes that the amount of oil burned had no effect on the inside temperature. Neither did the outside temperature. The only effect of burning oil seemed to be that it reduced the outside temperature.
A second econometrician, observing the same data, concludes that causality runs in the opposite direction. The only effect of an increase in outside temperature is to reduce the amount of oil burned. An increase in V will cause a decline in M, and have no effect on P.
But both agree that M and V are irrelevant for P. They switch off the furnace, and stop wasting their money on oil.
The KV cache does require O(T) memory (where T is the number of tokens we wish to generate), which ain’t cheap (see: $NVDA).
How big is the KV cache? Well, for each token, we store the following number of many bytes (the first 2 is because we assume bf16 precision, so 2 bytes per parameter, and the second 2 is because we have to store both the K and the V tensors):
Note that, by assumption, n_heads * d_head = d_model = d, so the number of bytes is 4 * the number of layers * d.
For GPT-3, we have 96 layers with a d_model of 12288, so we need 4.72 MB per token. It would thus require 5.6GB to generate 2048 tokens.
Having said this, to generate a sequence of a given length with a given model, we still need to use the exact same amount of memory as the KV cache requires, we just throw it away at the end of each forward pass. So we don’t need more memory. In a sense, the KV cache is free (modulo some tedious bookkeeping, at least in Jax).
How does this change for more modern architectures, like Mistral 7B? Mistral 7b uses Grouped query attention (as does Llama2— almost as if there’s an overlap in authors or something…) and sliding window attention.
In GQA, you share the KV projection across multiple heads, either a single KV projection across all heads (MQA) or into multiple groups (GQA). These are all equivalent to standard multi-head attention (MHA) with a smaller d_model. Earlier, we did the KV cache calculations assuming that the number of heads * the head dimension is equal to the model dimension, but for MQA/GQA we relax that assumption. As the KV cache formula is
we change this to be
where the number of heads * the head dimension is the effective model dimension. Thus, we see a linear decrease in the KV cache size as the number of KV heads decreases (one of the key motivating factors behind GQA/MQA).
The parameters of the Llama{1,2} models are given by:

So for Llama 2, the KV cache required per token is:

Without GQA, the 34B model would take 5x as much memory for the KV cache, and the 70B model would take 8x more memory.
Sliding window attention, another one of the Llama/Mistral tweaks, guarantees that we can cap the KV cache at the window size, which is 4096 for Llama7B.
Performance motivated architectural changes
As discussed, above, a LLM uses 24d^2 FLOPS per layer. Increasing the number of layers linearly scales the number of flops, and the number of parameters. Increasing the model width quadratically scales the model size. Note that this is because the number of parameters scales quadratically with d_model, as most of our layers go from a d_model input vector to a d_model output vector, so we have weight matrices that are (d_model, d_model) in size. Another way of putting this is that compute scales linearly with the number of parameters, and increasing d_model increases the number of parameters quadratically. Making the model 2x deeper doubles the parameters, but making it 2x wider quadruples the parameters.
Having said this, one advantage of a wider model is that it parallelizes better. To compute the Nth layer, you must first compute the preceding N-1 layers. This is difficult to parallelize efficiently, particularly during training, while it is much easier to split a single layer across GPUs via tensor paralellism. If you care mostly about latency, then you probably want to bias yourself towards a wider model.
Empirical analysis
I did this analysis using Colab (notebook). Here’s the high-level profile for a single forward pass (interactive profile on my website):
{kind=link}

We see that 4.88% of the overall time from this run was spent within this single forward pass. Of the forward pass, 1.98% is spent in attention, while 2.58% is spent in the MLP. Of the total time spent in the forward pass, 40% of the time is in the attention layer, and 53% in the MLP. Within the attention layer, the time is being spent on 4 different linear layers, 2 of them taking approximately equal time (linear_1, linear_2), one of them taking 50% more (linear_3), and one of them taking twice as long as the first two (linear_0). My guess is that the linear_0 is calculating the Query embedding, while linear_1/2 are calculating the Key and Value embeddings. Note how much quicker the calculation is because of the smaller number of KV heads! GQA makes a tangible difference, even though the attention mechanism being used (xformers.ops.memory_efficient_attention) requires that the QKV embeddings be broadcasted to the same size.
If we go back to our theoretical analysis, it predicted that 2/3rds of the time would be calculating the FFN, and 1/3rd on calculating attention. That’s roughly in line with what we see; we spend slightly more time calculating attention than the MLP, but I suspect that’s because the MLP is executing a very well-optimized path for Torch.
Performance changes
I then ran a number of experiments with Llama2 where I swept over the model width and depth. These are the results:

This is really interesting. We see basically no change in speed for the two models with a hidden size of 1024 and 1536 (1.10s vs 1.11s), and only a minor one (1.15s vs 1.10s) for the 1024 vs 2048 model. However, when we compare the models with hidden dimensions of 2048 (1.15s), 3072 (1.41s), and 4096 (1.82s), we start to see what looks like linear scaling!
My explanation is that there’s non-trivial overhead from dispatching the kernels and actually running the matmuls. This was run on a T4 (specs), which, although dated by modern standards, still has 65 TFLOPS of bf16 compute. If we multiply two 1024x1024 matrices together, that requires 1GFLOP of compute, so we can (theoretically) multiply 65000 1024x1024 matrices together per second. In practice, we’d only get 60-80% of that, but that’s still 40000 matmuls per second. A lot of this advantage comes the massive number of cores that modern GPUs have. A T4 has 2560 CUDA cores, each running at between 585 and 1590 MHz. As a result, any task that can be parallelized will do well, but those that require sequential calculation will not be as optimized. I think that’s what we’re seeing here- there’s not enough parallelism to actually occupy the GPU.
The transformer depth causes performance to behave exactly as you’d expect: inference time increases linearly with depth. There’s some noise when it comes to the deepest models, but it’s pretty well-behaved.
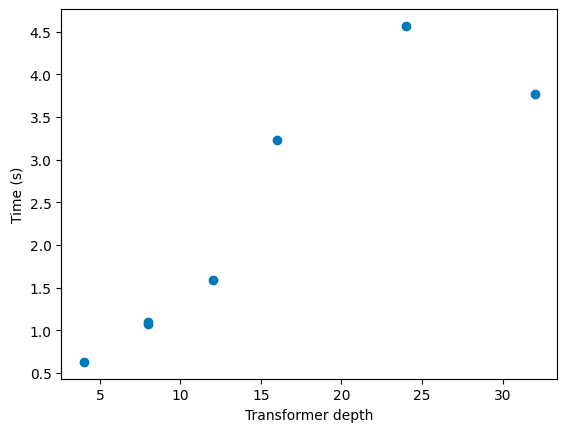
I then calculated the cost as we generate more tokens (I did 10 runs for each number of tokens, to reduce the noise):

It’s exactly linear, as you’d expect, because Llama2 uses a KV cache. If we look at the reserved memory, we see the KV cache working as expected (somewhat):

We see that the model has a jump of ~2.1MB every 20 tokens. As this model has d_model of 1024 and 8 hidden layers, it needs 4 * num_layers * d_model bytes of memory, or 4 * 8 * 1024 bytes = 32KB of memory per token. We should only need 640KB of memory. It’s unclear where the extra 3x overhead comes from. I suspect the answer is an inefficient implementation.
Why the negative percentages?