
Papers I’ve read this week: Image generation
A discussion of 4 seminal image generation papers

I’ve been reading about a lot of image generation models lately, focusing on the OpenAI papers, as they seem like the basis of a lot of future work. Here, I discuss 4 seminal papers:
CLIP
DALL-E
GLIDE
DALL-E 2
CLIP
This isn’t an image generation paper per se, but is used by a lot of them as the embedding scheme. The main idea behind the paper is to predict which caption goes with which image as a way of doing self-supervised learning from a dataset of (image, text) pairs. If this works, then the result will be aligned text and image embeddings, which would be really useful for a variety of applications, e.g. search, image generation, zero-shot classification, etc.
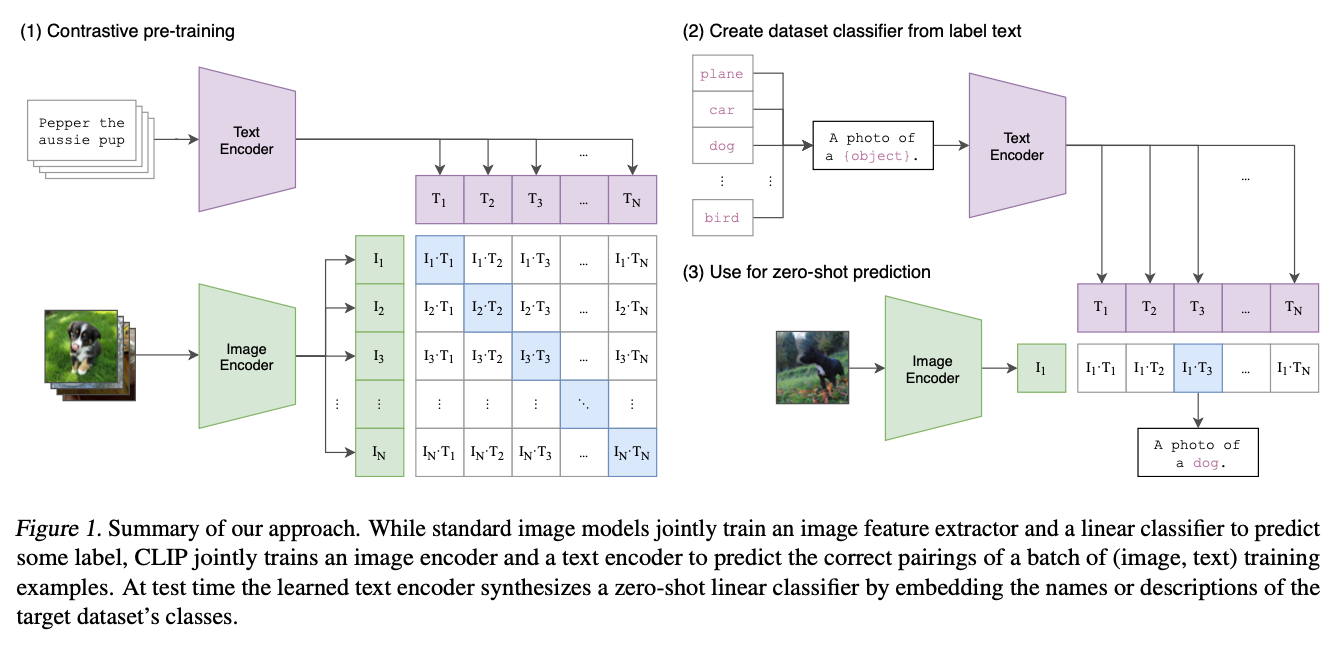
The architecture is pretty simple; they jointly train an image and a text encoder on a batch of N (image, text) pairs using a contrastive loss which predicts which of the N^2 pairings actually occurred. They maximize the cosine similarity of the image & text embeddings of the real pairs, while minimizing the cosine similarity of the N^2 - N incorrect pairs. Pseudo-code:

Once the model is trained, they’re able to use it for a variety of tasks. My favourite is zero-shot classification; they ask the model to assign probabilities to the text “{class}” and use that as the probability that the image is a member of the class. Interestingly, by using the prompt “A photo of a {class}.”, they got a 1.3% improvement in model accuracy.
Using this zero-shot classification scheme, the results are quite impressive: they’re able to match the accuracy of the original ResNet-50 on ImageNet zero-shot, without training on any of the ImageNet dataset.
They experiment with two separate image models, one based on various ResNet architectures, and one based on ViT. They find that the ViT performs better, and is actually cheaper to train than the ResNet.
This is really interesting to me, as this is a prompt that humans were able to come up with. I’m curious what the optimal prompt is. An experiment I’d love to run would be to use some sort of RL driven approach to explore the token space and find the best prompt for such a classification scheme; I suspect there’s more performance that can be squeezed out of it.
In any case, CLIP is remarkable because it’s a very straightforward embedding method that works quite well, and is able to scale to massive amounts of data. It’s further evidence that large scale self-supervised pre-training is the way to go to achieve SOTA performance with neural nets.
DALL-E
This paper uses a transformer to auto-regressively model text & image tokens as a single stream of data to enable zero-shot image generation
For a long time, image generation was dominated by GANs, but they’re tough to scale. I’m not sure exactly what the problems are with scaling them; mode collapse is always cited, but I’m not up to speed with that literature. I’m going to dive into it for a future “Papers I’ve read this week.”
DALL-E was the first (afaik) model to massively scale autoregressive transformers on large image datasets. They trained a 12B parameter model on 250M (image, text) pairs using a two-stage training procedure:
They train a discrete VAE to compress each 256x256 RGB image into a 32x32 grid of image tokens, each element of which can assume 8192 possible values.
They concatenate up to 256 BPE-encoded text tokens with the image token.
The concatenated embedding is fed to an autoregressive transformer to model the joint distribution over the text & image tokens, which is equivalent to maximizing the standard ELB.
Let x denote the images, y the captions, and z the tokens for the encoded RGB image. They model the distribution via
i.e. they learn two models— p_\theta, the distribution over the RGB images generated by the dVAE decoder from the image tokens, and p_\psi, the joint distribution over the text and image tokens modelled by the transformer.
The loss has the lower bound
The bound only holds when \beta is 1, but they play with other values, and find it useful to use bigger ones.
I wrote up a derivation on my blog, as it was unclear to me where the lower bound came from. As we’re maximizing the loss, maximizing the lower bound is fine. q_\phi here is the distribution over the image tokens generated by the dVAE encoder given the RGB image x.
This paper, like many image generation papers, has to abstract away from pixels:
using pixels directly as image tokens would require an inordinate amount of memory for high-resolution images
We see this in many image generation models, as pixels are really expensive, while if you can learn a mapping from text/image tokens into some latent space, you can then learn a separate mapping from the latent space to pixel space, and then upgrade this separately. This modularity is particularly useful for production systems, as you don’t have to train everything to experiment with your system.
They first train the dVAE to learn a visual codebook by maximizing the lower bound using the gumbel-softmax relaxation (they have to use this as q_\psi is a discrete distribution, so we can’t use the reparametrization gradient to maximize it).
Then, they fix \phi and \theta, and learn the prior distribution over the text & image tokens by maximizing the ELB with respect to \psi, using a 12B parameter transformer for p_\psi. The model is fairly standard, using BPE to encode the caption, and getting image tokens from the dVAE encoder logits. The transformer itself is a decoder where each image token attends to all text tokens.
Shockingly, given the current state of the art in LLMs, this model only takes up 24GB of memory, so it could be trained on a single A100 (as they have 40GB of memory). They only had access to V100s for whatever reason (which only have 16GB of memory) so they had to use ZeRO to train their model on multiple machines.
They used PowerSGD, which I had never heard of before, which dramatically reduced the amount of communicated needed between GPUs, as they were able to compress the parameter gradients by a factor of 85%.
To sample from their model, they rerank the samples from the transformer using CLIP, which assigns a score for how well the image matches the caption; they generate N samples and select the top K to show to the user.
GLIDE
In Glide, a 3.5B parameter diffusion model is used to turn text embeddings into images. They explore two different guiding methods: CLIP, and classifier-free guidance. The model is quite straightforward, using a vanilla transformer to generate embeddings, and a vanilla diffusion model to output images from the embeddings. The CLIP guidance method is interesting; it’s described as:

They train two models:
A 1.2B parameter text encoding transformer which takes in the text tokens as input and outputs an embedding
A 1.5B parameter upsampling diffusion model, which takes in the embeddings and outputs the final image
this seems like a really logical architecture- I'm surprised it was novel? I need to read more of the preceding literature to understand the context. To evaluate their model, they use a bunch of tasks to evaluate their model, such as in-painting, composition, corgi images, etc. I'm curious how much of this was introduced by them vs introduced by others- I don't have the context to understand that, but the way they evaluate their models seems very similar to how all subsequent models are evaluated.
DALL-E 2
DALL-E 2 uses a two-step training process: first, train CLIP, then, train a text-to-image generation process from it. In the text-to-image generation process, they have two models:
A prior, which takes in the CLIP text embedding, and outputs an image embedding,
The decoder, which takes in the CLIP image embedding and outputs the image.
The models are both diffusion models, using
They explored two different priors, one an autoregressive (AR) prior using a ??? to iteratively build the image embedding from a sequence of discrete codes, and the other, a diffusion prior, which directly models the image embedding. It’s worth noting that both methods involve iteratively building the embedding; the AR prior iteratively builds a sequence which is the embedding, while the diffusion model iteratively refines the embedding.

Given that the diffusion model is preferred by human evaluators, that seems to do better. This makes sense— the diffusion model is able to modify any part of the embedding, while the AR model is only able to modify the element at a specific index. There are interesting implications to language modelling here— maybe Sander Dieleman is right, and diffusion language models are the next big thing.
Comparing DALL-E 2 to GLIDE, the main difference is that image generation is split into two steps:
Transforming the text embedding into an image embedding
Generating the actual image
Naively, it makes sense to me to combine these two steps and train the whole thing end-to-end, but as DALL-E 2 was a significant improvement over GLIDE, it seems like my intuition is false.
In particular, it’s not clear to me why we need to go from CLIP to CLIP, isn’t the whole premise of CLIP that the text and image embeddings are in the same latent space (and thus equivalent)? I posted this comment on Twitter, and I got some interesting comments:
Sharif noted that while CLIP should, in theory, be encoding “both text and images into the same latent space, there’s still a large gap between the embeddings from each modality”, pointing me to a paper about understanding this modality gap.
Benjamin hypothesized that there is a loss of spatial information due to the spatial encoder mapping the (H, W, C) images to (embedding_dimension,) embedding vectors.
To me, this indicates that CLIP isn’t nearly as good as we would hope, and there’s significant room to improve it.
Future papers
I haven’t read, but plan to read, the following papers, possibly for a “diffusion models” version of “Papers I’ve read this week”:
Generative modelling through SDEs: https://arxiv.org/abs/2011.13456
Latent diffusion models: https://arxiv.org/abs/2112.10752
Classifier guidance: https://arxiv.org/abs/2105.05233
Classifier-free guidance: https://openreview.net/forum?id=qw8AKxfYbI
ControlNet: https://arxiv.org/abs/2302.05543
> In particular, it’s not clear to me why we need to go from CLIP to CLIP
I also found this confusing when I read the DALLE2 paper (see https://www.lesswrong.com/posts/XCtFBWoMeFwG8myYh/dalle2-comments).
Not long after that paper, Google came out with Imagen (https://arxiv.org/abs/2205.11487), which is reportedly better than DALLE2 (in a head to head comparison) despite using a much more obvious approach:
- conditioning with cross-attention to a text encoder, as in GLIDE
- but, using a powerful pretrained text encoder rather than training one end-to-end from scratch
The Imagen paper focuses on the case where the text encoder is T5, but they also tried using CLIP's text encoder, and got very similar (if slightly worse) results.
Before I saw Imagen, I thought "this unCLIP idea does not make sense theoretically, but apparently it helps in practice." After I saw Imagen, I wasn't even sure anymore than it helped it practice. (It is superior to GLIDE, which doesn't have the benefit of access to CLIP, but it can be beaten by a more relevant baseline that does have access to CLIP and uses it in the obvious way.)
The Imagen approach, of GLIDE-style conditioning with a pretrained CLIP text encoder, was also used independently in
- Katherine Crawson's v-diffusion (https://github.com/crowsonkb/v-diffusion-pytorch), developed before DALLE2 or even GLIDE existed
- Stable Diffusion, which Crawson also worked on